CaltechCameraTraps

Caltech Camera Traps (CCT)
Camera traps are motion- or heat-triggered cameras that are placed in locations of interest by biologists in order to monitor and study animal populations and behavior. When a camera is triggered, a sequence of images is taken at approximately one frame per second. The cameras are prone to false triggers caused by wind or heat rising from the ground, leading to empty frames. Empty frames can also occur if an animal moves out of the field of view of the camera while the sequence is firing. Once a month, biologists return to the cameras to replace the batteries and change out the memory card. After it has been collected, experts manually sort camera trap data to categorize species and remove empty frames. These cameras enable the automatic collection of large quantities of image data, but the time required to sort images severely limits data scale and research productivity. Automating the process using computer vision would make camera trap research scalable and efficient.
The goal of this dataset is to provide a testbed for computer vision researchers to investigate how well their models are able to generalize to unseen locations. The main challenge is generalizing to a diverse set of unseen camera trap locations that have been captured both during the day and at night that are not present in the training set. The dataset can be used to predict if images contain an animal, to detect that animal, and to classify the animal. Some images contain other objects (e.g. people or vehicles) that can trigger the cameras but are not of interest. The animals of interest can be very small, partially occluded, or exiting the frame - you sometimes have to look hard to find them. There may also be a small number of incorrect annotations in the training set.
This dataset is a superset of the data used in our ECCV18 paper “Recognition in Terra Incognita” and was used in the iWildCam 2018 FGVCx competition as part of the FGVC^5 workshop at CVPR18 and the iWildCam 2019 FGVCx competition as part of the FGVC^6 workshop at CVPR19. Please email sbeery at caltech dot edu if you have questions or problems with the dataset.
Details and Evaluation
The dataset contains 243,187 images from 140 camera locations.
For the iWildCam Challenge 2018 we provided a split containing 106,428 training images from 65 different camera locations and 12,719 validation images from 10 new locations not seen at training time. The test set contained 124,040 images from 65 locations that are not present in the training or validation sets. The location id (location) is given for all images.
The evaluation metric for the iWildCam18 challenge was overall accuracy in a binary animal/no animal classification task i.e. correctly predicting which of the test images contain animals.
This dataset has class-level annotations for all images, as well as bounding box annotations for a subset of 57,864 images from 20 locations. The subset containing bounding boxes was used for our ECCV18 paper, “Recognition in Terra Incognita.”
Annotation Format
We follow the annotation format of the COCO dataset and add additional fields in order to specify camera-trap specific information. These fields include a location id, a sequence id, the number of frames in that sequence, and the frame number of the individual image. Note that not all cameras take sequences of images at a single trigger, so for some images the number of frames in the associated sequence will be one.Each training image has a category_id representing its class, and some images also have a bbox. The annotations are stored in the JSON format and are organized as follows:
{
"info" : info,
"images" : [image],
"categories" : [category],
"annotations" : [annotation]
}
info{
"year" : int,
"version" : str,
"description" : str,
"contributor" : str
"date_created" : datetime
}
image{
"id" : str,
"width" : int,
"height" : int,
"file_name" : str,
"rights_holder" : str,
"location": int,
"datetime": datetime,
"seq_id": str,
"seq_num_frames": int,
"frame_num": int
}
category{
"id" : int,
"name" : str
}
annotation{
"id" : str,
"image_id" : str,
"category_id" : int,
# These are in absolute, floating-point coordinates, with the origin at the upper-left
"bbox": [x,y,width,height]
}
Terms of Use
By downloading this dataset you agree to the terms outlined in the Community Data License Agreement (CDLA).
Data
The data can be downloaded from the Labeled Information Library of Alexandria
Images, splits, and annotations from the Caltech Camera Traps-20 (CCT-20) data subset used in our ECCV18 paper can be seperately downloaded:
- All ECCV18 images 22 GB (Contains 1.3K images not included in the iWildCam 2018 Challenge Dataset)
- Link
- Running
md5sum eccv_18_all_images.tar.gzshould produce04c0f27699d0643fcabfd28992d1189f
- All ECCV18 annotations 2975KB
- Link
- Running
md5sum eccv_18_all_annotations.tar.gzshould produce90bf977d435c72139404c13b7ab39982
- Separate json files for ECCV18 data split 2927KB
- Link
- Running
md5sum eccv_18_annotations.tar.gzshould produce66a1f481b44aa1edadf75c9cfbd27aba
- Smaller ECCV18 images, image width resized to 1024 pixels
- Link
- Running
md5sum eccv_18_all_images_sm.tar.gzshould produce8143c17aa2a12872b66f284ff211531f
Notes on the ECCV Paper “Recognition in Terra Incognita”
Abstract
It is desirable for detection and classification algorithms to generalize to unfamiliar environments, but suitable benchmarks for quantitatively studying this phenomenon are not yet available. We present a dataset designed to measure recognition generalization to novel environments. The images in our dataset are harvested from twenty camera traps deployed to monitor animal populations. Camera traps are fixed at one location, hence the background changes little across images; capture is triggered automatically, hence there is no human bias. The challenge is learning recognition in a handful of locations, and generalizing animal detection and classification to new locations where no training data is available. In our experiments state-of-the-art algorithms show excellent performance when tested at the same location where they were trained. However, we find that generalization to new locations is poor, especially for classification systems.
Clarifications
We ran three types of experiments in the paper, separating animal classification from animal detection in order to analyze their contributions to the generalization gap when testing on novel environments.
- Full image classification using Inception V3 for 15 animal classes, pretrained on ImageNet.
- Cropped ground-truth box animal classification using Inception V3 for 15 animal classes, pretrained on ImageNet.
- Faster-RCNN detection on full images for a single combined class “animal”, using both Resnet 101 and Inception-Resnet-V2 with atrous backbones, pretrained on COCO.
Data Challenges
Camera trap data provides several challenges that can make it difficult to achieve accurate results.
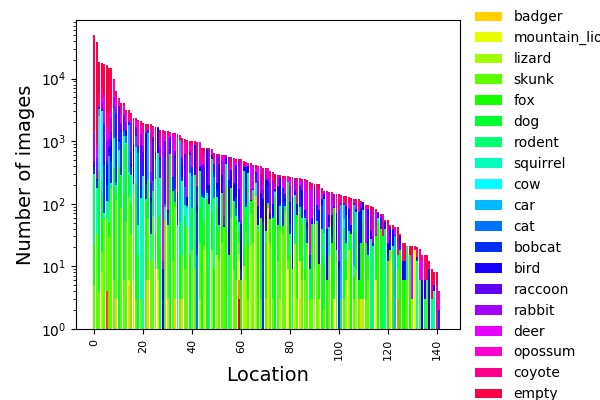
Class distributions
Each location has its own unique distribution of classes, and overcoming these priors can be difficult. The distribution of classes at each location is visualized in the plot below.
Illumination:
Images can be poorly illuminated, especially at night. The example below contains a skunk to the center left of the frame.

Motion Blur:
The shutter speed of the camera is not fast enough to eliminate motion blur, so animals are sometimes blurry. The example contains a blurred coyote.

Small ROI:
Some animals are small or far from the camera, and can be difficult to spot even for humans. The example image has a mouse on a branch to the center right of the frame.

Occlusion:
Animals can be occluded by vegetation or the edge of the frame. This example shows a location where weeds grew in front of the camera, obscuring the view.

Perspective:
Sometimes animals come very close to the camera, causing a forced perspective.

Weather Conditions:
Poor weather, including rain or dust, can obstruct the lens and cause false triggers.

Camera Malfunctions:
Sometimes the camera malfunctions, causing strange discolorations.

Temporal Changes:
At any given location, the background changes over time as the seasons change. Below, you can see a single loction at three different points in time.

Non-Animal Variability:
What causes the non-animal images to trigger varies based on location. Some locations contain lots of vegetation, which can cause false triggers as it moves in the wind. Others are near roadways, so can be triggered by cars or bikers.
Acknowledgements
We would like to thank Erin Boydston (USGS) and Justin Brown (NPS) for providing us with data. This material is based upon work supported by the National Science Foundation Graduate Research Fellowship Program under Grant No. 1745301. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.